Stockage : de NBD/RAID à Longhorn
Trois tentatives de stockage distribué avant d'adopter Longhorn comme solution finale
Le choix d’une solution de stockage distribué sur Raspberry Pi s’est avéré être la partie la plus complexe de ce projet. Trois approches ont été testées avant d’arriver à une solution stable.
Solution finale : Longhorn
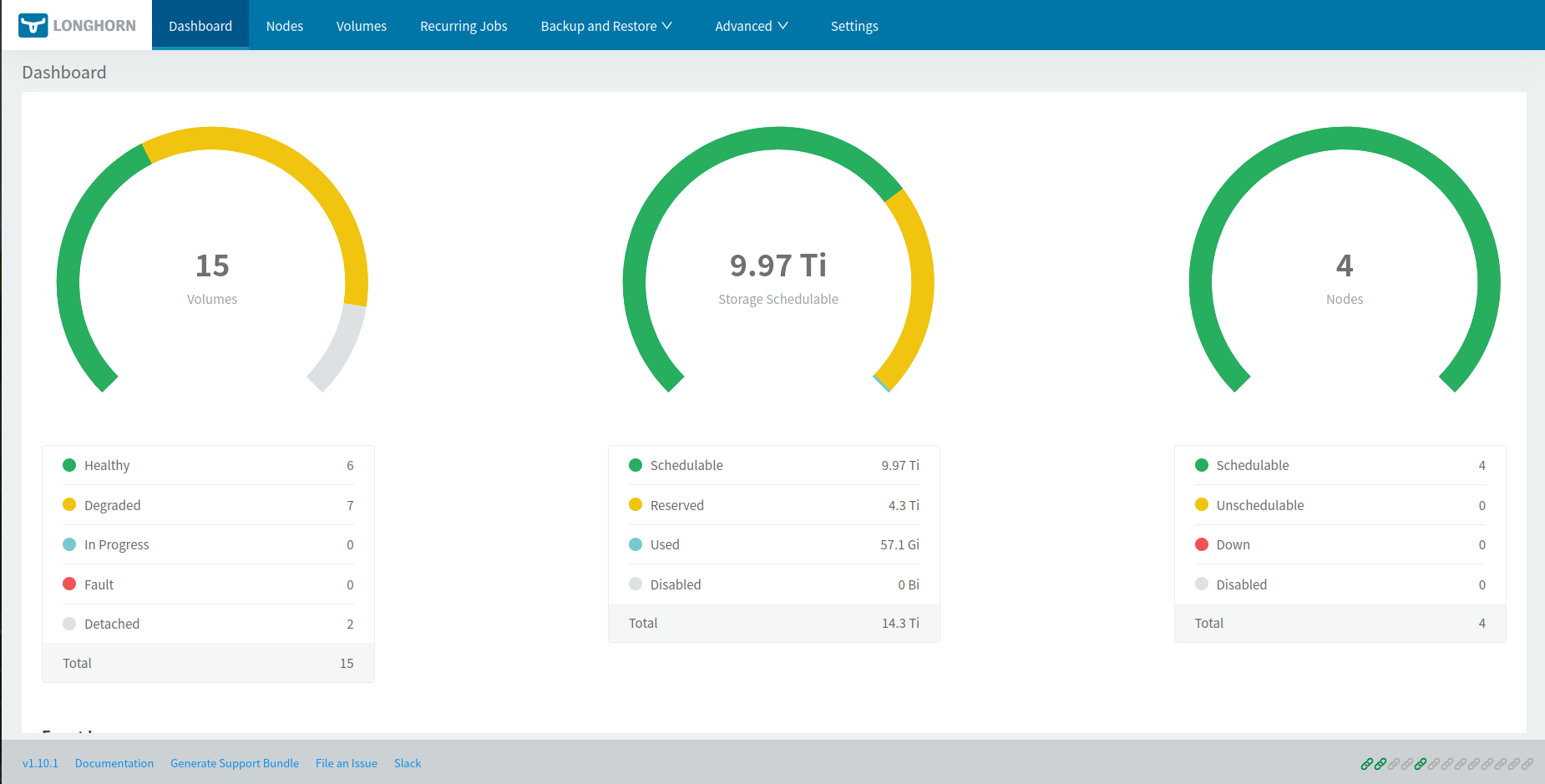
Longhorn a été retenu pour sa résilience native, son interface de gestion et sa bonne intégration avec k3s. Avec 2 réplicas par volume, chaque donnée est dupliquée sur deux nœuds différents — si un Pi tombe, les données restent accessibles.
Prérequis sur chaque nœud
sudo apt install nfs-common open-iscsi util-linux
sudo systemctl enable --now iscsid
sudo modprobe iscsi_tcp
sudo modprobe nbd
echo -e "iscsi_tcp\nnbd" | sudo tee /etc/modules-load.d/longhorn.confInstallation via Helm (depuis le control plane)
helm repo add longhorn https://charts.longhorn.io
helm repo update
helm install longhorn longhorn/longhorn \
--namespace longhorn \
--create-namespace \
--set defaultSettings.defaultDataPath="/media/DATA"Passer les réplicas à 2
Par défaut Longhorn crée 3 réplicas, ce qui est trop pour 3 nœuds workers avec des disques de capacité modeste. Pour modifier ce paramètre :
- Ouvrir l’UI via port-forward :
kubectl -n longhorn-system port-forward svc/longhorn-frontend 8080:80 - Naviguer dans Settings → General → Default Replica Count et passer la valeur à
2.
Test : créer un PVC de validation
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-test-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 1Gikubectl apply -f test-pvc.yamlDans l’onglet Volume de l’UI Longhorn, le volume doit apparaître en état Healthy avec 2/2 réplicas.
Ajouter le control plane au stockage
Par défaut, le taint CriticalAddonsOnly=true:NoExecute posé lors de l’installation de k3s empêche Longhorn de scheduler ses pods de stockage sur le control plane. Pour l’utiliser comme quatrième nœud de stockage :
# Vérifier le taint actuel
kubectl describe node cube04 | grep Taints
# Supprimer le taint (le tiret final signifie "supprimer")
kubectl taint nodes cube04 CriticalAddonsOnly=true:NoExecute-Ensuite, préparer le disque sur cube04 (formater, créer /media/DATA, ajouter à /etc/fstab, monter). Longhorn détectera automatiquement le quatrième nœud.
Optimisation des montages disque
Sur chaque nœud disposant d’un disque USB, éditer /etc/fstab pour réduire les écritures et se protéger contre la corruption en cas de coupure :
/dev/sda1 /media/DATA ext4 noatime,nodiratime,sync,errors=remount-ro 0 2| Option | Effet |
|---|---|
noatime | Ne met pas à jour l’heure d’accès à la lecture — réduit les écritures |
nodiratime | Idem pour les répertoires |
sync | Les écritures sont immédiates, sans cache — le plus sûr en cas de coupure |
errors=remount-ro | En cas de corruption détectée, remonte en lecture seule plutôt que de corrompre davantage |
Forcer une vérification du disque au prochain boot :
sudo tune2fs -c 1 /dev/sda1Solutions historiques
v1 — RAID 5 sur NBD
Idée : monter un disque USB sur chaque worker, les exposer via NBD (Network Block Device) au control plane, puis assembler un RAID 5 logiciel avec mdadm pour obtenir un volume unique résilient.
Installation
Sur chaque worker, installer et configurer le serveur NBD (/etc/nbd-server/config) :
[generic]
user = root
group = root
includedir = /etc/nbd-server/conf.d
[export1]
exportname = /dev/sda1
authfile =Sur le control plane, connecter les disques distants et créer le RAID :
sudo nbd-client <IP-cube01> -N export1 /dev/nbd1
sudo nbd-client <IP-cube02> -N export1 /dev/nbd2
sudo nbd-client <IP-cube03> -N export1 /dev/nbd3
sudo apt install mdadm
sudo mdadm --create --verbose /dev/md0 --level=5 \
--raid-devices=3 /dev/nbd1 /dev/nbd2 /dev/nbd3
sudo mkfs.ext4 /dev/md0
sudo mkdir /media/DATA
sudo mount /dev/md0 /media/DATAPourquoi ça n’a pas marché : la latence réseau sur des liens Gigabit entre Pi est trop élevée pour que RAID 5 soit exploitable. Les temps de réponse en écriture étaient inacceptables, et une simulation de panne de disque a montré que la reconstruction du RAID aurait pris plusieurs jours.
v2 — NFS + mergerfs
Idée : chaque worker exporte son disque en NFS, le control plane monte les quatre partages et les fusionne avec mergerfs en un seul point de montage, lui-même ré-exporté en NFS pour le cluster Kubernetes via le driver CSI NFS.
Installation
Sur chaque worker :
sudo apt install nfs-kernel-server
sudo mount /dev/sda1 /media/DATA
sudo chown nobody:nogroup /media/DATA
# /etc/exports :
# /media/DATA *(rw,async,no_subtree_check)
sudo exportfs -a
sudo systemctl restart nfs-kernel-serverSur le control plane :
sudo apt install nfs-common mergerfs
sudo mkdir /media/cube01_drive /media/cube02_drive /media/cube03_drive /media/cube04_drive
sudo mount -t nfs <IP-cube01>:/media/DATA /media/cube01_drive/ -o rw,nfsvers=3,async
sudo mount -t nfs <IP-cube02>:/media/DATA /media/cube02_drive/ -o rw,nfsvers=3,async
sudo mount -t nfs <IP-cube03>:/media/DATA /media/cube03_drive/ -o rw,nfsvers=3,async
sudo mount /dev/sda1 /media/cube04_drive
sudo mergerfs \
/media/cube01_drive:/media/cube02_drive:/media/cube03_drive:/media/cube04_drive \
/media/DATA/ -o allow_otherCôté Kubernetes, installation du driver CSI NFS et création d’une StorageClass par défaut :
helm install csi-driver-nfs csi-driver-nfs/csi-driver-nfs \
--namespace kube-system --version v4.9.0apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-cluster
provisioner: nfs.csi.k8s.io
parameters:
server: cube04
share: /media/DATA/
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: truekubectl patch storageclass local-path \
-p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
kubectl patch storageclass nfs-cluster \
-p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'Pourquoi ça n’a pas marché : mergerfs expose un volume unique sans réplication — si un disque cède, toutes les données qui y sont stockées sont perdues. Après une défaillance de disque réelle, la totalité du stockage est devenue inaccessible. Absence totale de tolérance aux pannes.
v3 — GlusterFS
Idée : GlusterFS est un système de fichiers distribué qui gère nativement la réplication. Avec replica 2, chaque bloc de données est mirrored sur deux nœuds différents.
Installation
Sur chaque nœud :
sudo apt install -y glusterfs-server
sudo systemctl enable --now glusterd
sudo mkfs -t ext4 /dev/sda1
sudo mkdir -p /media/glusterfs
echo "/dev/sda1 /media/glusterfs ext4 defaults 0 0" | sudo tee -a /etc/fstab
sudo mount -aDepuis un nœud, former le cluster et créer le volume répliqué :
sudo gluster peer probe cube01
sudo gluster peer probe cube02
sudo gluster peer probe cube03
sudo gluster volume create gv0 replica 2 transport tcp \
cube01:/media/glusterfs/brick1 \
cube02:/media/glusterfs/brick2 \
cube03:/media/glusterfs/brick3 \
cube04:/media/glusterfs/brick4 force
sudo gluster volume start gv0Sur chaque nœud, monter le volume partagé :
sudo apt install -y glusterfs-client
sudo mkdir -p /mnt/gluster
sudo mount -t glusterfs cube04:/gv0 /mnt/glusterCôté Kubernetes, création d’un PersistentVolume pointant directement sur /mnt/gluster — fonctionnel, mais sans provisionnement dynamique.
Pourquoi ça n’a pas marché : les performances en écriture étaient extrêmement mauvaises, pires encore que NFS. GlusterFS n’est pas conçu pour des liens Gigabit entre des Raspberry Pi, et le surcoût de la réplication le rendait inutilisable pour des workloads réels comme Immich ou Gitea.